graph LR
A(("🤗 Accelerate#32;"))
A --> B["CLI Interface#32;"]
A --> C["Training Library#32;"]
A --> D["Big Model<br>Inference#32;"]
Scaling Model Training with More Compute, How Do They Do It?
Who am I?
- Zachary Mueller
- Technical Lead for the 🤗 Accelerate project
- API design geek
Understanding GPU Usage
- We can somewhat estimate the memory usage in vanilla full-fine-tuning of models
- Requires certain assumptions (that I’ll be covering):
- Adam optimizer
- Batch size of 1
Understanding GPU Usage
General estimate (bert-base-cased, 108M params):
- Each parameter is 4 bytes
- Backward ~= 2x the model size
- The optimizer step ~= 4x the model size (1x model, 1x gradients, 2x optimizer):
| dtype | Model | Gradients | Backward pass | Optimizer step | Highest |
|---|---|---|---|---|---|
| float32 | 413.18 MB | 413.18 MB | 826.36 MB | 1.61 GB | 1.61 GB |
| float16 | 413.18 MB* | 619.77 MB | 826.36 MB | 826.36 MB | 826.36 MB |
*All estimations were based off the Model Estimator Tool
Understanding GPU Usage
This works fine for small models, we have cards with anywhere from 12-24GB of GPU memory (on the GPU-poor side).
But what happens as we scale?
Here’s llama-3-8B (8.03B parameters)
| dtype | Model | Gradients | Backward pass | Optimizer step | Highest |
|---|---|---|---|---|---|
| float32 | 28.21 GB | 28.21 GB | 56.43 GB | 112.84 GB | 112.84 GB |
| float16 | 28.21 GB* | 42.32 GB | 56.43 GB | 56.43 GB | 56.43 GB |
Well, I don’t have 56GB of GPU memory in a single card, let alone 112GB.
What can we do?
Distributed Training
Kinds of Training
- Single GPU:
- No distributed techniques at play
- Distributed Data Parallelism (DDP):
- A full copy of the model exists on each device, but data is chunked between each GPU
- Fully Sharded Data Parallelism (FSDP) & DeepSpeed (DS):
- Split chunks of the model and optimizer states across GPUs, allowing for training bigger models on smaller (multiple) GPUs
Fully Sharded Data Parallelism
Fully Sharded Data Parallelism
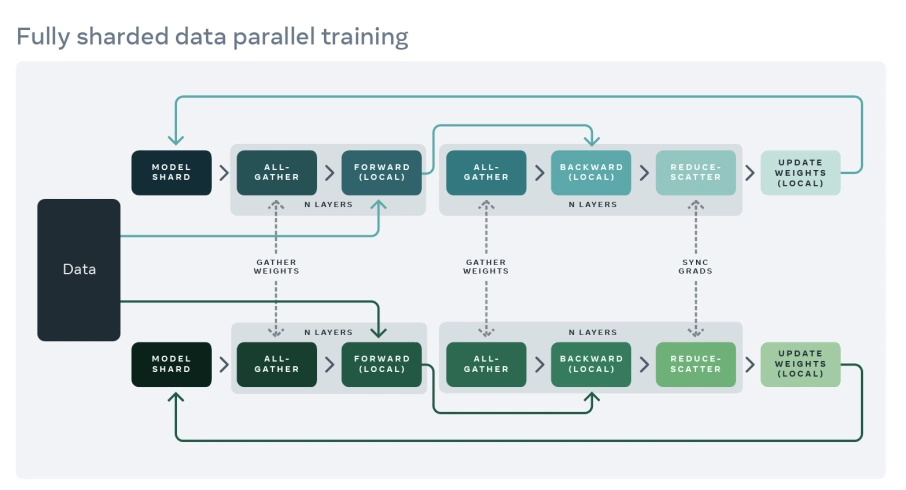
FSDP: Getting parameter specific
- Different parameters can dicatate how much memory is needed for total GPU training across multiple GPUs
- These include how model weights are sharded, gradients, and more.
- I’ll cover some important ones I needed when doing a Full-Fine-Tune of Llama-3-8B without PEFT on 2x4090’s
sharding_strategy
- Dictates the level of divving resources to perform
FULL_SHARD: Includes optimizer states, gradients, and parametersSHARD_GRAD_OP: Includes optimizer states and gradientsNO_SHARD: Normal DDPHYBRID_SHARD: Includes optimizer states, gradients, and parameters but each node has the full model
auto_wrap_policy:
- How the model should be split
- Can be either
TRANSFORMER_BASED_WRAPorSIZE_BASED_WRAP TRANSFORMER/fsdp_transformers_layer_cls_to_wrap:- Need to declare the layer
- Generally
transformershas good defaults
SIZE/fsdp_min_num_param:- Number of total parameters in a shard
offload_params:
- Offloads the parameters and gradients to the CPU if they can’t fit into memory
- Allows you to train much larger models locally, but will be much slower
Case: FFT of Llama-3-8B with
fsdp_offload_paramson 2x4090 GPUs was 72hrs, vs ~an hour or two when using 1xH100
cpu_ram_efficient_loading and sync_module_states
- Uses the idea behind big model inference/the
metadevice to load in the model to the GPU in a low-ram scenario - Rather than needing
model_size*n_gpusRAM, we can load the model on a single node and then send the weights directly to each shard when the time is right viasync_module_states
Tying this to 🤗 Accelerate
Tying this to 🤗 Accelerate
- So far we’ve covered the theory, but how do we put it into practice
- By using a library that’s at the heart of the entire open-source ecosystem
- Nearly all of 🤗
axolotlfastaiFastChatlucidrainskornia
Are you using it and you don’t even know?
What is 🤗 Accelerate?
A CLI Interface
accelerate config- Configure the environment
accelerate estimate-memory- How to guess vRAM requirements
accelerate launch- How to run your script
Launching distributed training is hard
How can we make this better?
accelerate launch
accelerate config
- Rely on
config.yamlfiles - Choose to either running
accelerate configor write your own:
fsdp_config.yaml
compute_environment: LOCAL_MACHINE
distributed_type: FSDP
fsdp_config:
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
fsdp_backward_prefetch: BACKWARD_PRE
fsdp_cpu_ram_efficient_loading: true
fsdp_forward_prefetch: false
fsdp_offload_params: false
fsdp_sharding_strategy: FULL_SHARD
fsdp_state_dict_type: SHARDED_STATE_DICT
fsdp_sync_module_states: true
fsdp_use_orig_params: false
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 8A Training Library
A Training Library: The Code
from accelerate import Accelerator
accelerator = Accelerator()
dataloader, model, optimizer scheduler = (
accelerator.prepare(
dataloader, model, optimizer, scheduler
)
)
for batch in dataloader:
optimizer.zero_grad()
inputs, targets = batch
# inputs = inputs.to(device)
# targets = targets.to(device)
outputs = model(inputs)
loss = loss_function(outputs, targets)
accelerator.backward(loss) # loss.backward()
optimizer.step()
scheduler.step()A Training Library: How Scaling Works
- Accelerate’s DataLoaders and schedulers work off of a sharding mindset
- Rather than repeating the same data across
nnodes, we instead split it - Speeds up training linearly
- Given a batch size of 16 on a single GPU, to recreate this across 8 GPUs you would use a batch size of 2
- This also means the scheduler will be stepped
nGPUs at a time per “global step”
A Training Library: Mixed Precision
- This may be a bit different than your “normal” idea of mixed precision.
- We do not convert the model weights to BF16/FP16
- Instead we wrap the forward pass with
autocastto convert the gradients automatically - This preserves the original precision of the weights, which leads to stable training and better fine-tuning later on.
- If you use
.bf16()weights, you are STUCK in bf16 perminantly
A Training Library: Mixed Precision
- Let’s tie that back up to the model estimator with neat tools like NVIDIA’s TransformerEngine
| Optimization Level | Computation (GEMM) | Comm | Weight | Master Weight | Weight Gradient | Optimizer States |
|---|---|---|---|---|---|---|
| FP16 AMP | FP16 | FP32 | FP32 | N/A | FP32 | FP32+FP32 |
| Nvidia TE | FP8 | FP32 | FP32 | N/A | FP32 | FP32+FP32 |
| MS-AMP O1 | FP8 | FP8 | FP16 | N/A | FP8 | FP32+FP32 |
| MS-AMP O2 | FP8 | FP8 | FP16 | N/A | FP8 | FP8+FP16 |
| MS-AMP O3 | FP8 | FP8 | FP8 | FP16 | FP8 | FP8+FP16 |
DeepSpeed vs Fully Sharded Data Parallelism
- Extremely similar, however mostly used different naming conventions for items and slight tweaks in the implementation
| Framework | Model Loading (torch_dtype) |
Mixed Precision | Preparation (Local) | Training | Optimizer (Local) |
|---|---|---|---|---|---|
| FSDP | bf16 | default (none) | bf16 | bf16 | bf16 |
| FSDP | bf16 | bf16 | fp32 | bf16 | fp32 |
| DeepSpeed | bf16 | bf16 | fp32 | bf16 | fp32 |
To learn more, check out the documentation or join my office hours
Key Takeaways:
- You can scale out training with
accelerate, FSDP, and DeepSpeed across multiple GPUs to train bigger models - Techniques like
FP8can help speed up training some and reduce computational overhead - Comes at a cost of end-precision and locking model weights for futher fine-tunes if not careful
Some Handy Resources
- 🤗 Accelerate documentation
- Launching distributed code
- Distributed code and Jupyter Notebooks
- Migrating to 🤗 Accelerate easily
- Big Model Inference tutorial
- DeepSpeed and 🤗 Accelerate
- Fully Sharded Data Parallelism and 🤗 Accelerate
- FSDP vs DeepSpeed In-Depth